こんにちは、ピリカ開発チームの九鬼です。
弊社が開発しているタカノメ自動車版では、クラウド上にて撮影動画中のごみを検知しています(下図例)。
本機能を安定化するにあたり、開発環境において試行錯誤した経緯を共有いたします。

タカノメ自動車版とは?
タカノメ自動車版は、内製のスマートフォンアプリを車両に搭載し、道路を走行することで各地のごみ分布を可視化するサービスです。得られたごみ分布の結果から、どこにごみが多いか、また清掃活動などを行った結果がどうだったかを定量的に判断することができるようになります。
本サービスの実現にあたり、プライバシー処理済みの撮影動画をアプリからGCPにアップロードします。GCP上で、学習済みの深層学習モデルを用いて動画内にあるポイ捨てごみを検出します。最後に、検出結果を基に散乱状況をマップ上に可視化します。
本サービスの詳細については、以下ページをご覧ください。
1. 初期設計
最初、以下の構成でごみ検出を行う設計としました。まず、前日に撮影された動画一覧を取得し、全動画に対してバックグラウンドタスクを発行します。このタスクをCloud Run上のごみ検出処理用のコンテナインスタンスで処理するようにしました。この時点では、Cloud Runの設定はデフォルト値のままでした。
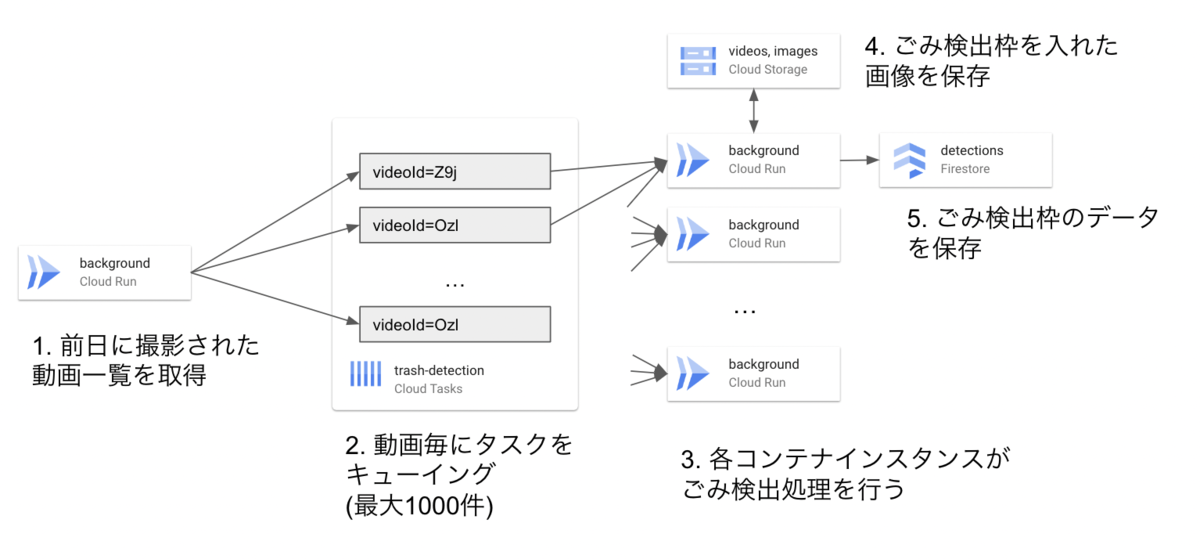
発生した問題
Cloud Runのデフォルトスペック(1vCPU, 512MiB)では、メモリ容量が足りずクラッシュしていました。ごみ検出ではなく、ごみ検出のための深層学習モデルのロードの時点でメモリ不足に陥っていました。
2. backgroundサービスのvCPU, メモリ量見直し
いくつかの検証より、メモリ量は4GiB強だけ必要であることがわかりました。Cloud Runでは、メモリ量=8GiBに設定するにはvCPU≧2とする必要があります。そのため、
- vCPU = 2
- メモリ量 = 8GiB
とし、再度ごみ検出を試みました。
発生した問題
Cloud Runがデフォルトの5分でタイムアウトしました。このとき、Cloud Runの当該サービスの設定は
- vCPU = 2
- メモリ量 = 8GiB
- コンテナあたりの最大受付リクエスト数(containerConcurrency) = 80 (デフォルト値)
- 最大同時コンテナインスタンス数(maxScale) = 100
でした。処理負荷の1つのリクエストで1つの動画のごみ検出を行うのが限界でしたが、そこに最大80リクエストが殺到したためにタイムアウトが発生していました。
3. スケーリング設定見直し
各コンテナインスタンスに処理が集中しないよう、以下の通り設定し直しました。
backgroundサービスの設定
- コンテナあたりの最大受付リクエスト数(containerConcurrency) = 2
- 最大同時コンテナインスタンス数(maxScale) = 200
- リクエストのタイムアウト時間(timeout) = 15分
vCPU = 2なので、1コンテナインスタンスあたり2リクエストまで同時に受けるようにしています。また、コンテナインスタンスを200とし、同時に400動画分を捌けるようにしました。
発生した問題
本来の動画よりも1.5倍近くの量の動画が処理されていました。内訳を見ると、前日だけでなく前々日の動画も処理されていました。
発生した理由ですが、ローカルでは日本時間で前日を出していました。一方で、クラウド上ではUTCでの前日(=日本時間での2日前)となっていました。さらに、集計日時の終端を指定していなかったために、2日前のAM0:00 ~ 現在日時AM0:00までを余分に集計することになってしまいました。
def __find_date_range(self) -> datetime: begin_date = datetime.combine( date.today() - timedelta(days=1), time()) return begin_date
4. 前日の判定を修正
前述の問題を受けて、ごみの検出区間を下記の通り修正しました。
def __find_date_range(self) -> tuple[datetime, datetime]: jst_now = datetime.now(pytz_timezone('Asia/Tokyo')) # pytz_timezoneはpytzモジュールのtimezoneのエイリアス time_jst_midnight = time(tzinfo=jst_now.tzinfo) begin_date = datetime.combine( jst_now - timedelta(days=1), time_jst_midnight) end_date = datetime.combine( jst_now, time_jst_midnight) return begin_date, end_date
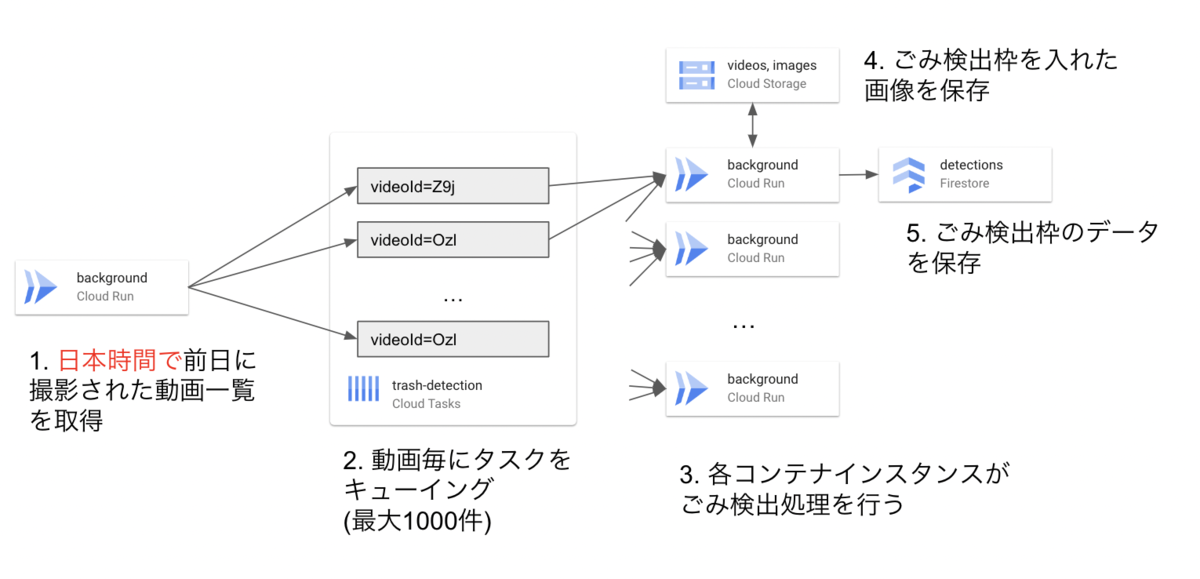
発生した問題
ごみ画像のCloud Storageへの保存時、ときより429エラーによりタスクが失敗することがありました。Cloud Storageでは、1プロジェクトあたり同時に1000件/秒だけファイルを書き込むことができるものの、それを越えて書き込みしていました。この原因として、画像作成の際にごみの数の分だけ余分に保存するバグが混在していました。
4. リトライ可能なエラーはリトライし、なおかつ画像は1フレームあたり1回だけ保存する
上記問題を踏まえ、以下構成の通り修正しました。
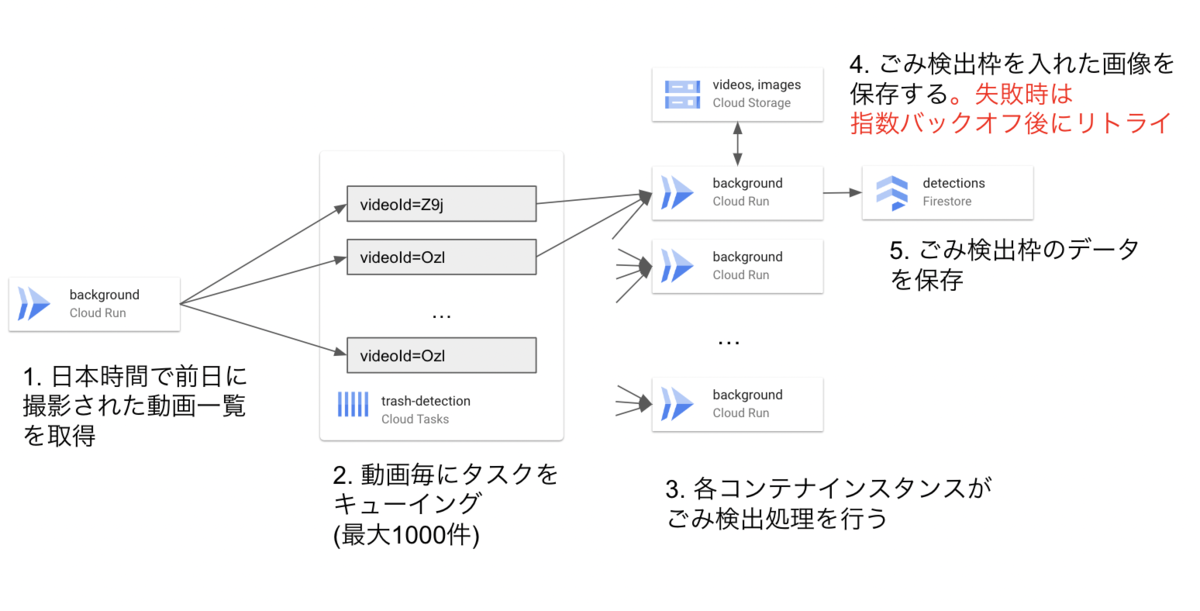
発生した問題
1日に撮影した動画が多い場合、ごみ検出タスク発行が10分以内に間に合わずタイムアウトしました。2タスクの発行ごとに約0.5~0.6秒を要しており、動画数が1000件を越えると600秒に間に合わなかったためです。
5. 動画ごとのタスク発行用に、日時を分割
最終的に以下の構成になりました。ごみの検出を行う期間を複数に等分割し、ごみ検出タスク発行を分散しました。これにより、ごみ検出タスク発行が複数のコンテナに分散され、タイムアウトが発生しないようになりました。
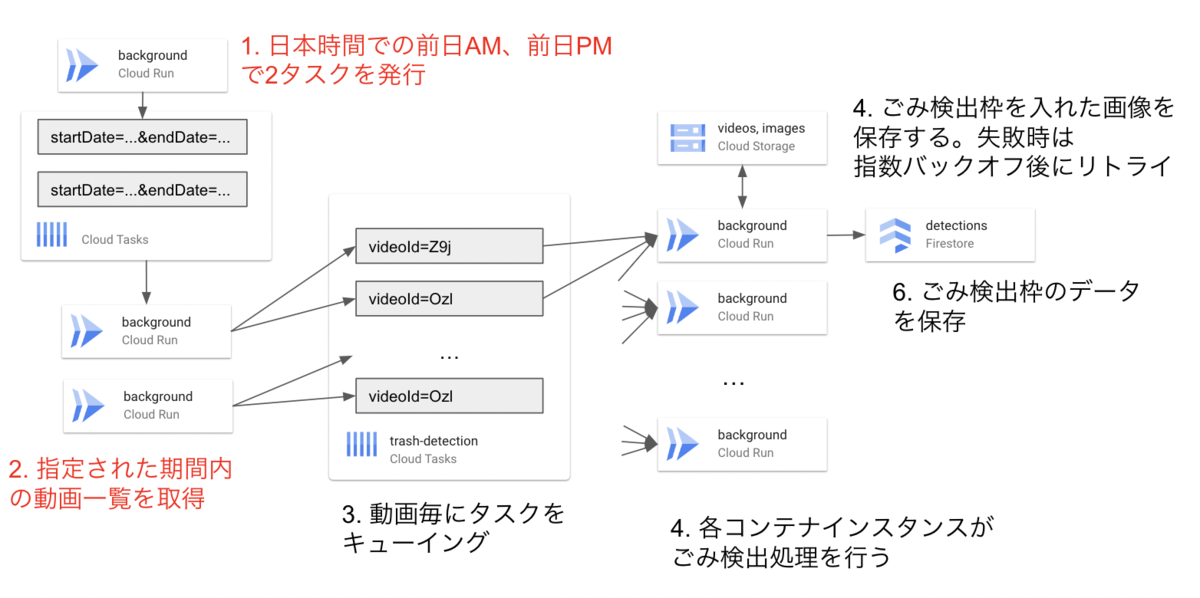
得られた知見
本件を通して、以下の知見が得られました。
- 1つの実行インスタンスからタスクを発行する件数を一定以下に抑えるよう設計する
- 複数タスクを同時に走らせるとき、Cloud Storageの書き込み制限数などのリクエスト上の制限を意識して設計する
- Cloud Taskのキュー設定およびCloud Runなどの実行設定をみて、事前にどれくらいの件数を、どれくらいの期間で捌けるようにするかを設計する。
本ケースでは大量のデータを、1つ1つ高負荷な処理で加工する必要がありました。そのため、それに見合った処理フローの調整が必要でした。クラウドとローカルで時差が違ったり、計算リソースの不足があったりと様々な考えるべきポイントがあり、あらためてCloud RunやCloud Task等の公式リファレンスを読むのが大事でした。
以上、ご覧いただきありがとうございました!