こんにちは。 ピリカ開発チームの伊藤です。
ピリカでは6月1日より、ピリカサポーターズクラブを開始しました。 まだご覧になっていない方はこちらをご覧ください。
ピリカサポーターズクラブをはじめるにあたって新しいシステムを構築しました。 ピリカの開発チームのリソースは潤沢ではない中、全く新しいシステムを作るのはとても大きなチャレンジです。
社内からも「開発のリソースが潤沢でないならSNSピリカに注力すべき」という意見はありましたが、開発チームでは単に新しいシステムを作るだけではなく、この開発を「SNSピリカの開発を今後少ないリソースで効率的に進めるために必要な基盤の実験」としても位置付けていました。
この開発を通じて得たことのまとめとして、ピリカサポーターズクラブの構成やデプロイの仕組みをご紹介したいと思います。
SNSピリカの開発で抱えている問題
SNSピリカは2011年の創業当初からGoogle App Engineを使って開発されています。 SNSピリカには開発環境と本番環境のGCPプロジェクトがあり、テストはApp Engineのバージョン指定デプロイで環境を分けて実施しています。
これでは不十分なこともあり、より細かい用途ごとのGCPプロジェクトを作りたいと考えていました。 しかしながら、すべて手動でリソースが作られており、簡単に環境を分けることができません。 本番系へのデプロイは自動化されているとはいえ、テスト環境のデプロイはエンジニア任せとなっているため、テスターやマネージャー層が開発中の環境確認をするためには一手間かかる状況にあります。
また、App Engineはサービス開始当初は無料で使える範囲が広く安価なサービスでありましたが、現在ではCloud Run等と比較して費用の高いサービスとなっています。 SNSピリカのApp Engineのインフラ費用は、株式会社ピリカ全体としてGoogle Cloudに払っている費用の中でも大きな割合を占めており、この点でも刷新を推し進めて運営費を下げていく必要があります。
目指した基盤のすがた
これらの問題を解消するため、ピリカサポーターズクラブの開発では以下のようなポイントを念頭に置きました。
- 徹底的なデプロイの自動化を行う
- 一部例外を除いてインフラ操作をすべてIaaCで実施。WebのCloud Consoleを触る操作を限界まで排除する。
- IAMの管理をバイネームで行わず、すべてグループで管理する
- プロジェクトの追加・削除を手軽に行えるようにする。
- その気になれば、エンジニア1人ごとに開発プロジェクトを作るくらいのことができるようにする。
- Pull Requestごとに環境がデプロイされるようにする
- データベース等は共有しているが、プログラムはPRごとに環境が作られる
- Cloud Runをメインの実行リソースに据えて、インフラ費用を下げる
- ローカルでもGCP上とほぼ同じ状態かつローカル編集に適した状態のインフラを立ち上げることができる
- monorepo構成を採用し、システム全体を管理できるように構成する。
- 引き続き、サーバーレスサービスを中心において安価に運営できるようにする
- 後々、SNSピリカでも移行が計画しやすい構成にする
- この観点から、Kubernetesではなかった
これを実現するため、これまでのSNSピリカでも一部使ってきた開発要素であるTerraform、Cloud Run、そしてCloud Load Balancingを主要な要素として採用・活用しながら設計しました。
ピリカサポーターズクラブのビルド/デプロイ構成
ピリカサポーターズクラブには、CI/CDを管理する「ビルドプロジェクト」と、本番・検証などそれぞれの環境となる「サービスプロジェクト」があります。
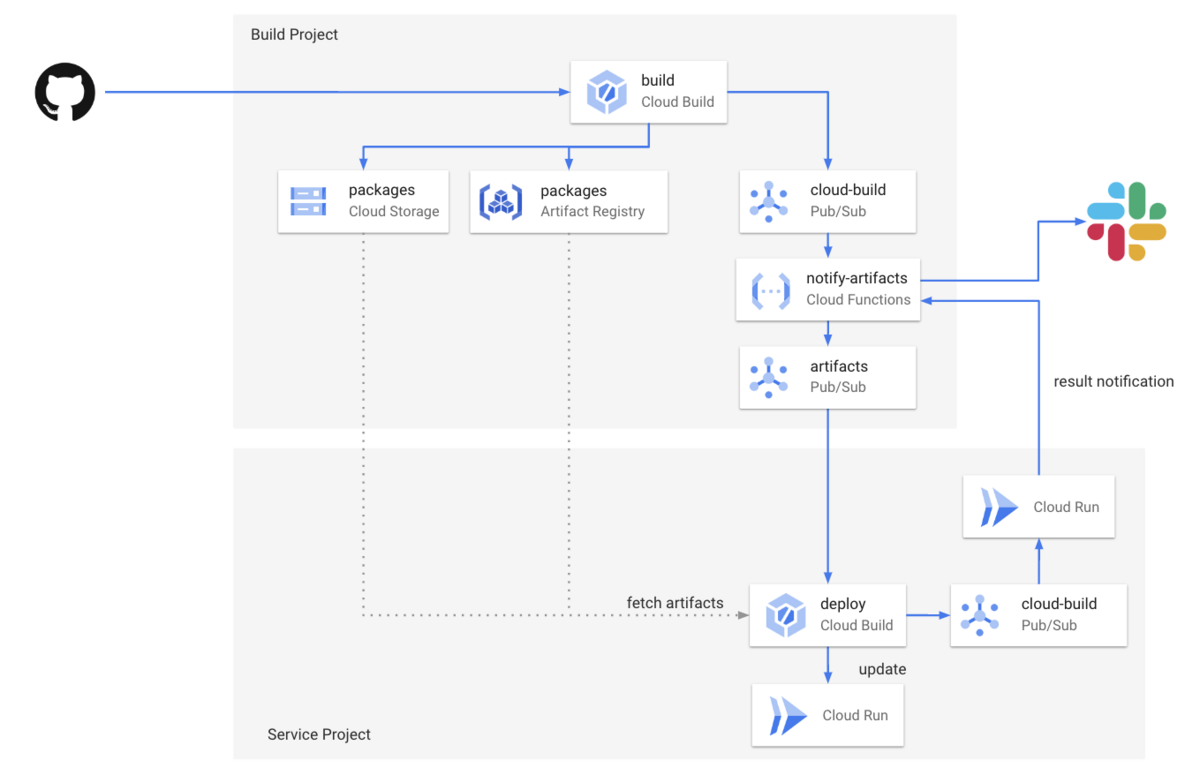
GitHubにコミットされると、ビルドプロジェクトのCloud BuildでDockerコンテナとデプロイパッケージがビルドされます。デプロイパッケージには各種メタデータと、Terraformスクリプトが含まれています。 Cloud BuildのPub/Sub通知を元に、Cloud Functionsが動作し、デプロイに必要な情報が含まれた新規アーティファクト通知がPub/Subに送られます。 このようにビルドプロジェクトとデプロイプロジェクトで分けておくことで、複数のプロジェクトにデプロイする際にビルドにかかる時間を1本化して短縮できるだけでなく、手動でのみ可能で強い権限が必要になるCloud BuildとGitHubの連携をビルドプロジェクト初回設定時の1回だけで済みます。
ピリカサポーターズクラブのビルド構成には「デプロイステージ」という、開発・検証・ステージング・本番のどの環境に対するものであるかという概念があります。
- Pull Requestやdevelopブランチからビルドされたものは開発
release/*もしくはhotfix/*ブランチからビルドされた場合は検証- gitタグからビルドされた場合はステージング
- 本番はステージ向けにビルドされたgitタグを指定して手動でCloud Buildトリガーを実行
アーティファクト通知のPub/Subのトピックはそれぞれのデプロイステージに分かれており、サービスプロジェクトの構成時にどのトピックを使用するかを構成して必要なアーティファクト通知のみ受信します。 これにより、開発環境や検証環境が複数あっても、開発ステージごとのデプロイが通知されるという動作が可能になっています。
デプロイが完了すると、Cloud BuildのPub/Sub通知からCloud Runをトリガーして、ビルドプロジェクトの通知APIにWebhookコールバックしてSlackに完了通知されます。
ビルドプロジェクトでのビルド
ビルドプロジェクトでは、リポジトリに含まれているcloudbuild.yamlの定義を元に、プロジェクトのソースコードを以下のステップでビルドします。
- フロントエンドのReactをビルドする
- サービスプロジェクト用のTerraform関連のスクリプトをリポジトリのソースから集約してzipにまとめる
- フロントエンドのDockerコンテナをビルドする
- バックエンドのDockerコンテナをビルドする
リビジョンタグはgitのブランチ名かタグ名から自動的に生成しています。
留意しないといけない点として、Cloud Runの63文字の文字数制限と、-以外の記号が使えない文字種の制限があります。
これらの制限はDNSのドメインのラベルの文字数制限からきていますが、このあと Cloud Load Balancingの構成時にURLマスクで(tag)-(service|admin).(service root domain) の構成にすることを考えた場合より短い文字数にしておく必要があります。
この制限に収まるように、以下のようなルールで変換しています。
# トラフィックタグの正規化 # - 先頭が数字の場合は先頭にvを付与 # - ドット、スラッシュ、アンダースコアをハイフンに変換 # - 最大文字数は46文字となるため、16文字をサービス側の文字数として残し、末尾30文字を使用 # - 削った結果先頭/末尾がハイフンになる場合は削除 # - 小文字に変換 if [[ "${traffic_tag:0:1}" =~ [0-9] ]]; then traffic_tag="v$traffic_tag" fi traffic_tag=$(echo $traffic_tag \ | sed -e "s/[\.\/_]/-/g" \ | sed -E 's/^.*(.{30})$/\1/' \ | sed -E 's/^-+//' \ | sed -E 's/-+$//' \ | tr '[:upper:]' '[:lower:]' \ )
アーティファクト通知の取り扱い
Cloud Buildはビルド結果をCloud Pub/Subに通知する機能を持っています。これをするには以下の準備をしておく必要があります。参考
cloud-buildsという名前の Pub/Sub トピックを作成しておく- このトピックに対して
service-<project-number>@gcp-sa-cloudbuild.iam.gserviceaccount.comが Cloud Build サービスエージェントロールを持っている
このトピックにはプロジェクト内のCloud Buildビルドの状態が全て流れてくるため、サービスプロジェクト側に流れるには不適切な情報が流れる可能性もあるため、必要な情報のみにフィルタしつつ、追加情報を含めた状態でアーティファクト通知プロジェクトに送ります。
この処理には Cloud Functions を用いることにしました。例えば以下のようなハンドラで処理することができます*1。
def process_notify_artifacts(event): project = os.getenv('GCP_PROJECT') topic = os.getenv('ARTIFACTS_TOPIC') callback_url = os.getenv('CALLBACK_URL') # サービスプロジェクトのビルド結果をコールバックするWebhook URL # ペイロードにCloud Buildのビルド情報が入っている data = json.loads(base64.b64decode(event['data'])) build_id = data.get('id') # 進行中のステータスだったらスキップ status = data.get('status') if status in ['PENDING', 'QUEUED', 'WORKING']: return "" # タグにもビルドのメタデータを持たせている # 通知対象外のビルド構成であればスキップ tags = data.get('tags') or [] # type: list[str] if 'build' not in tags and 'deploy' not in tags: return "" # ビルドステージ、gitのコミットIDを取得する stage = None commit = None for tag in tags: if tag.startswith('commit-') and not tag.startswith('commit-build-'): commit = tag.replace('commit-', '') if tag.startswith('deployStage-'): stage = tag.replace('deployStage-', '') if stage is None: print("stage is None") return "" # ビルドに指定されていたパラメータも得ることができる substitutions = data.get('substitutions') or {} # type: dict[str, str] ref_name = substitutions.get('REF_NAME') or '' pr_number = substitutions.get('_PR_NUMBER') or '' repo_url = substitutions.get('_HEAD_REPO_URL') or '' version_tag = substitutions.get('_VERSION_TAG') # 成功してたらアーティファクト通知 if status == 'SUCCESS': artifact_location = data.get('artifacts', {})\ .get('objects', {}).get('location') if not artifact_location and stage and version_tag: # デプロイステージが production のときはビルドがなく通知だけ流れるのでパッケージ情報がない。 # ステージングで作られたpackageを使う artifact_stage = stage if artifact_stage == 'production': artifact_stage = 'stage' artifact_location = \ f"gs://{project}-packages/pirika-supporters-club" \ f"/{artifact_stage}/tags/{version_tag}/" if artifact_location: package_url = f"{artifact_location}package.zip" metadata_url = f"{artifact_location}metadata.json" # Pub/Sub通知ラッパーをインスタンス化して、 # 必要なデータを集約してartifacts-(stage)トピックに送信 # 内部ではJSONを組み立て、送信先トピックをstageから特定し、publishしているのみ。 publisher = ArtifactsPublisher(project, topic) publisher.publish_artifacts( stage=stage, commit=commit or '', ref_name=ref_name, pr_number=pr_number, repo_url=repo_url, package_url=package_url, metadata_url=metadata_url, callback_url=callback_url ) # Slack通知する # notify_slack(...) return {}
これにより、Pub/Subの artifacts-(deployStage) に必要な情報を含むメッセージがパブリッシュされます。
サービスプロジェクトでのデプロイ
ビルドプロジェクトのビルドが完了してアーティファクト通知トピックにデータが流れると、サービスプロジェクトのCloud Build Pub/Subトリガーによりサービスプロジェクトでビルドが実行されます。
プロジェクトを超えたPub/Subサブスクリプションについては、以前このブログでもご紹介しました。
サービスプロジェクトのCloud BuildはPub/Subトリガーで動作しますが、リポジトリの参照は持っていません。リポジトリの参照を持たないビルドトリガーは現状、TerraformなどのWeb Consoleを使わない方法でしか作ることができません。
以下のようなビルドステップでビルドが進行します。
- ビルドパッケージのZIPファイルをCloud Storageからコピーして取得する
- 取得したパッケージファイルをunzipする
- Terraformのバックエンド、環境設定ファイル、デプロイステージによる設定など、Terraform実行に必要な情報を出力する (configure)
- terraform apply を実行して基盤の反映を実施する
- terraform output を使い、Cloud Runのデプロイに必要な感情設定ファイルを作成する(export-outputs)
- Cloud Runをデプロイする (deploy-cloudrun)
- Identity-Aware Proxyの追加構成を行う (iap-setting)
Cloud Runのデプロイ
Cloud Runの更新はTerraformの中から行わず、別途コマンドを実行して実施しています。 これは、トラフィック0%でリビジョンタグが指定された状態で新しいイメージをデプロイするのがTerraformではできないためです。
そこで、Terraformの中ではCloud Runは初回に空のイメージでデプロイするようにし、以後は無視するようにしています。
resource "google_cloud_run_service" "service" { name = var.name location = var.gcp_region template { spec { containers { # 空イメージを指定 image = var.empty_image } service_account_name = var.service_account } metadata { name = "${var.name}-frontend-empty" } } lifecycle { # 変更を無視 ignore_changes = all } }
Cloud Runのデプロイはgcloud run deployコマンドでできます。 単に順番にデプロイを並べると、1つ1つのデプロイが完了するまで待ってしまうため、バックグラウンドでコマンドを実行させ、waitコマンドですべて待つようにしています。
#!/bin/bash -e current_dir=$(cd "$(dirname "$0")" && pwd) # package に含まれている環境変数をロード source "$current_dir/cloudrun-parameters.sh" # terraform outputs から取得して作られた環境変数をロード source "$current_dir/outputs.sh" # セッションシークレットを生成し、Secret Managerに書き込む # (初回に書き込まれているデフォルト値が残っている場合に、新しい値を生成して書き込む) session_secret=$(gcloud secrets versions access latest --secret=session-secret) if [ -z "$session_secret" ] || [ "$session_secret" = "none" ]; then echo "Write new session secret to secret manager" session_secret=$(openssl rand -base64 32) gcloud secrets versions add session-secret --data-file=<(echo "$session_secret") fi # 環境変数を作成 # 環境変数に , が含まれる場合は ^(char)^ を先頭に書くことで区切り文字を(char)に指定したものに変更可能 # https://cloud.google.com/run/docs/configuring/environment-variables?hl=ja#escaping ENV_VARS="^|^GCP_PROJECT=$PROJECT|REGION=$REGION|DEPLOY_STAGE=$DEPLOY_STAGE" # Secret Managerへの参照を設定 BACKEND_SECRETS="" BACKEND_SECRETS+="SECRET_VALUE1=secret_value_1:latest" BACKEND_SECRETS+=",SECRET_VALUE2=secret_value_2:latest" # 複数のバックグラウンドタスクを待機する関数 wait_pids() { for pid in "$@"; do echo "wait $pid" if ! wait "$pid"; then echo "Error detected" 1>&2 exit 1 fi done } pids=() gcloud run deploy service-frontend \ $no_traffic_flag \ --region "$REGION" \ --image "$APP_SERVICE_FRONTEND_IMAGE" \ --command "/app/run" \ --args "service" \ --service-account "$APP_SERVICE_ACCOUNT" \ --set-env-vars "$ENV_VARS" \ --ingress internal-and-cloud-load-balancing \ --allow-unauthenticated \ --tag "$APP_TRAFFIC_TAG" \ & pids+=($!) gcloud run deploy service-backend \ $no_traffic_flag \ --region "$REGION" \ --image "$APP_SERVICE_BACKEND_IMAGE" \ --command "/app/run" \ --args "service" \ --service-account "$APP_SERVICE_ACCOUNT" \ --set-env-vars "$ENV_VARS" \ --set-secrets "$BACKEND_SECRETS,SESSION_SECRET=session-secret:latest" \ --vpc-connector "$VPC_CONNECTOR" \ --ingress internal-and-cloud-load-balancing \ --vpc-egress "all-traffic" \ --allow-unauthenticated \ --tag "$APP_TRAFFIC_TAG" \ & pids+=($!) gcloud run deploy admin-frontend \ $no_traffic_flag \ --region "$REGION" \ --image "$APP_ADMIN_FRONTEND_IMAGE" \ --command "/app/run" \ --args "admin" \ --service-account "$APP_SERVICE_ACCOUNT" \ --set-env-vars "$ENV_VARS" \ --ingress internal-and-cloud-load-balancing \ --allow-unauthenticated \ --tag "$APP_TRAFFIC_TAG" \ & pids+=($!) gcloud run deploy admin-backend \ $no_traffic_flag \ --region "$REGION" \ --image "$APP_ADMIN_BACKEND_IMAGE" \ --command "/app/run" \ --args "admin" \ --service-account "$APP_SERVICE_ACCOUNT" \ --set-env-vars "$ENV_VARS" \ --set-secrets "$BACKEND_SECRETS" \ --vpc-connector "$VPC_CONNECTOR" \ --ingress internal-and-cloud-load-balancing \ --vpc-egress "all-traffic" \ --allow-unauthenticated \ --tag "$APP_TRAFFIC_TAG" \ & pids+=($!) # すべてのデプロイが完了するのを待つ wait_pids "${pids[@]}"
サービスプロジェクトの初期設定
Terraformを使った自動デプロイをする際、プロジェクトで一番最初のデプロイをどうするのかという問題があります。 ピリカサポーターズクラブのデプロイでは、デプロイパッケージに必ず初回設定用のスクリプト(seed.sh)を持たせて、プロジェクトの初回デプロイ時はCloud Shellにてデプロイパッケージを手動取得し、初回設定スクリプトを実行した後、terraform applyするようにしました。以後はCloud Buildのトリガーを受信できるようになりますので、ビルドプロジェクトでビルドを再実行することでソースが反映された状態を作る、というようにしています。
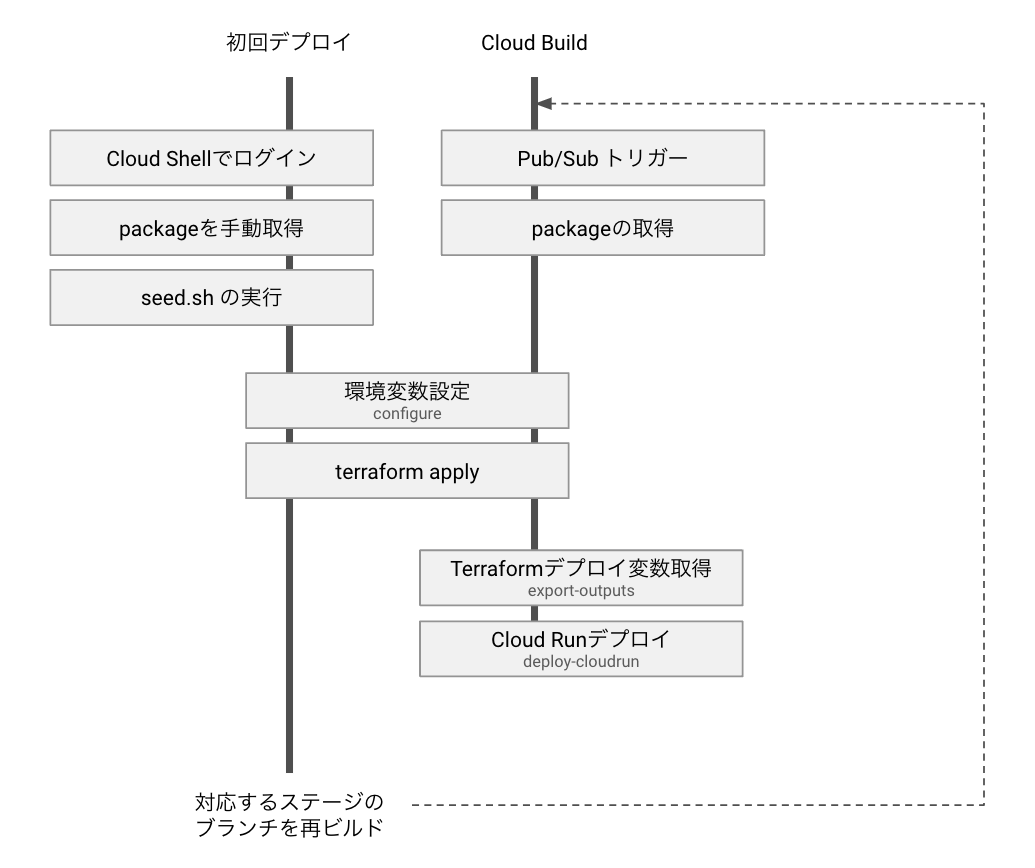
ちなみに、seed.sh では以下のようなことをしています。
#!/bin/bash -e PROJECT=$GOOGLE_CLOUD_PROJECT REGION=asia-northeast1 if [ "$PROJECT" = "" ]; then echo "GOOGLE_CLOUD_PROJECT is not set" exit 1 fi # この環境のメインドメインを指定する domain=$1 if [ "$domain" = "" ]; then echo "Usage: $0 <domain>" exit 1 fi # GCPオーナーとなるグループのIAMを設定しておく # (このアカウントは平時は使用しない) gcloud projects add-iam-policy-binding "${PROJECT}" --member group:<OWNER GROUP ADDRESS> --role roles/owner # Cloud Buildを実行するために最低限必要なAPIを有効化する gcloud services enable cloudresourcemanager.googleapis.com gcloud services enable secretmanager.googleapis.com gcloud services enable storage.googleapis.com gcloud services enable iam.googleapis.com gcloud services enable run.googleapis.com gcloud services enable cloudbuild.googleapis.com # tfstateを保存するためのバケットを作成する # バージョニングを有効化しておく tfstate_bucket="gs://${PROJECT}-tfstate" gcloud storage buckets create "$tfstate_bucket" --default-storage-class STANDARD --location "$REGION" gcloud storage buckets update "$tfstate_bucket" --versioning gsutil defstorageclass set REGIONAL "$tfstate_bucket" # 環境のメインドメインをSecret Managerに格納しておく。今後デプロイ時にconfigureで取得されるようにする echo -n "$domain" | gcloud secrets create service-domain --replication-policy=automatic --data-file=- # Cloud Build でデプロイするための Service Account を指定しておく # この後の権限設定で必要になるので、先に作っておく gcloud iam service-accounts create cloudbuild --display-name "Cloud Build Service Account"
データベースマイグレーション
これまで株式会社ピリカで作ってきたサービスはCloud DatastoreやFirestoreといったインスタンスを持たないスキーマレスデータベースを使ってきました。実行の費用が安いこと、マイグレーションのための停止作業が不要といったメリットがありますが、スキーマの整合性の維持や集計面で不便さがあることに課題を感じていました。
ピリカサポーターズクラブでは課金を伴うことも鑑みて、データ整合性の担保しやすさを求めてRDBMS(PostgreSQL)を採用することとしました。
RDBMSではデータベーススキーマの構成管理が必要となりますが、Pythonを使っているのでAlembicを用いています。 Alembicはコマンドを実行することでマイグレーション等の操作を行いますが、自動化とセキュリティの担保のため「データベースインスタンスを人間が直接触る操作はなくす」ということを徹底しています。 また、PostgreSQLユーザーを作るのではなく、Cloud SQL IAMデータベース認証を使うことでPostgreSQLにパスワードを設定しないようにしており、Alembicのコマンドを実行したとて認証することができなくなっています。
そのため、データベースマイグレーションも管理システムアプリケーションに実装されています。プログラム上からAlembicのコマンドを実行するには、alembic.command にある各種関数を使うことで実現できます。例えば、最新版にマイグレーションするには以下のような記述で実現することができます。
@dataclass class DatabaseConnector: instance_connection_name: str | None service_account: str | None database_host: str | None database_port: str | None database_name: str | None user: str | None password: str | None _engine: Engine | None = None def get_engine(self, **kwargs) -> Engine: if self._engine: return self._engine self._engine = sqlalchemy.create_engine( "postgresql+pg8000://", creator=self.get_connection, **kwargs ) return self._engine def get_connection(self) -> pg8000.Connection: if self.instance_connection_name: with Connector() as connector: return connector.connect( self.instance_connection_name, "pg8000", enable_iam_auth=True, user=self.service_account.removesuffix( ".gserviceaccount.com"), db=self.database_name, ip_type=IPTypes.PRIVATE ) else: return pg8000.connect( host=self.database_host, port=int(self.database_port), user=self.user, password=self.password, database=self.database_name, ) connector = DatabaseConnector(...) engine = connector.get_engine() config = alembic.config.Config('/app/alembic.ini') config.set_main_option('script_location', '/app/migrations') config.set_main_option('sqlalchemy.url', 'postgresql://:memory:') config.set_main_option('logger_root.url', 'postgresql://:memory:') config.attributes['connection'] = engine.connect() config.attributes['configure_logger'] = False command.upgrade('latest')
リビジョンの本番化(デフォルトリビジョン更新)
デプロイ後、動作が問題がないと確認されたリビジョンタグをデフォルトリビジョンにする操作についても、管理システムアプリケーションに実装しました。
しかし、Cloud RunのAPIでこれを実現する方法がよくわからなかったため、Cloud Pub/Subに本番化メッセージトピックを用意し、Cloud Build Pub/Subトリガーで本番化するCloud Buildタスクを実行するようにしました。
Cloud Run のデフォルトリビジョンを更新するには、gcloud run services update-trafficを使用します。
gcloud run services update-traffic "$service" --region "$region" --to-tags "$revision_tag=100"
この処理をCloud Buildにしたことで、本番化通知をビルドプロジェクトに送ってSlackで本番化完了通知ができるようになった副次的なメリットがありました。
権限設定
ここまで説明してきませんでしたが、サービスプロジェクトからビルドプロジェクトのリソースを参照するためには、サービスプロジェクトのCloud Buildからアクセスできるようにする必要があります。また、社内の他システムとの連携ではIdentity-Aware Proxy等GCPのサービスアカウントをベースとした認証を利用しています。
今回の構成では、サービスプロジェクトは動的な増減があるため、ビルドプロジェクトや連携先システムに都度つけ外しするのは手間がかかるだけでなく、間違いも起こり得ます。
そこで、サービスプロジェクトの初回デプロイ中に、プロジェクト内に作成されたサービスアカウントをGoogleグループに登録し、ビルドプロジェクト・連携先システムではそのグループに対してアクセス権を与えています。
アクセス権の設定のため、以下のようなGoogleグループを定義しています。これ以外にも開発者個人のGoogleアカウントを登録するGoogleグループをいくつか設定して、デプロイステージごとに適切にアクセス権が設定されるようになっています。
| 名称 | 登録されているアカウント | 利用目的 |
|---|---|---|
| Cloud Build Service Accounts | Cloud Buildビルドサービスアカウント、Cloud Buildサービスアカウント | ビルドプロジェクトのCloud Pub/Subへのサブスクライブ、Artifact Registry、デプロイパッケージのCloud Storageへのアクセス権限付与 |
| Application Service Accounts | Cloud Run実行サービスアカウント | 外部連携システムのIdentity-Aware Proxy等のアクセス権限設定 |
ピリカサポーターズクラブ のサービスインフラ構成
こうしてデプロイされたピリカサポーターズクラブのサービスインフラはこのような構成になっています。
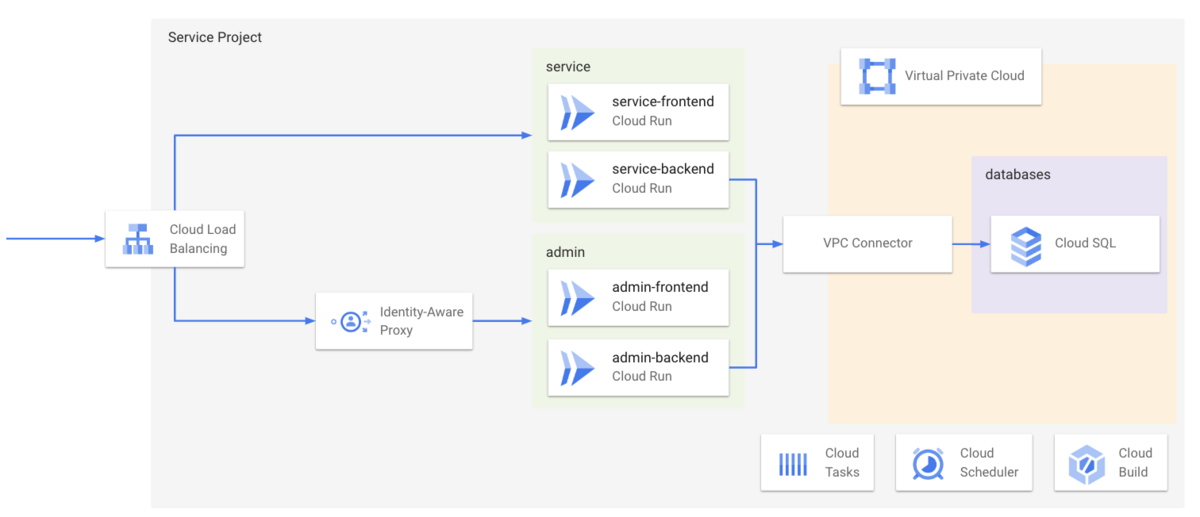
リクエストはすべて 1つの Cloud Load Balancing で受け付けます。 公開基盤はservice、管理基盤はadminと命名し、それぞれReactフロントエンドを配信するfrontendとPythonで構築されたAPIをホストするbackendを持ちます。
データベースにはCloud SQLをプライベートIP構成で構築し、Cloud RunからはServerless VPC Connectorを経由してアクセスされます。
Cloud Load Balancing の構成
Cloud Load Balancing では、URLマップを使って、ドメインおよびパスをベースにリクエストをサーバーレスNEGに振り分けています。
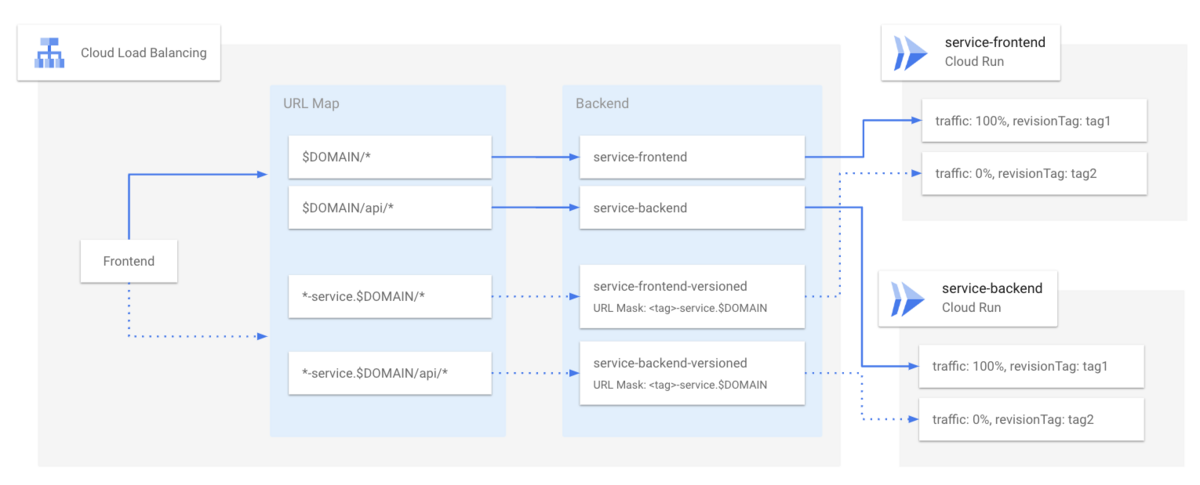
例えば、公開基盤のドメインに来たリクエストのうち、/api/ 以下は利用者向けのバックエンド、それ以外はフロントエンドのCloud Runに転送します。 また、特定のフォーマットのサブドメインへのリクエストが来た場合は、サーバーレスNEGをハンドルするバックエンドサービスで、URLマスクを使ってリビジョンタグを指定してルーティングします。
これをデプロイ時のGitブランチからのトラフィックタグ自動設定を組み合わせると、example.com というサイトに feature/example1 というブランチからデプロイされると、公開基盤の確認環境が feature-example1-service.example.com、管理基盤の確認環境がfeature-example1-admin.example.comでアクセスできるようになる、という仕組みになります。
Pull RequestへのPushをトリガーにしておき、デプロイ後のURLをSlackに通知されるようにしておけば、非エンジニアでも開発中のプログラムをすぐに確認できるようになります。
Cloud Load Balancingにワイルドカード証明書を指定した場合のIdentity-Aware Proxyのエラー
Cloud Load Balancingには、Certificate Managerで発行した固定ドメインとワイルドカードドメインが両方指定されている証明書を指定していました。
このとき、Identity-Aware Proxyが設定されているバックエンドに抜けるルートに対し、ワイルドカードで表される方のドメインを使用してアクセスすると、Error Code 52が表示されてアクセスが拒否される場合があります。
この場合、Identity-Aware Proxyに対して明示的に許可ドメインの設定を与えることでアクセスができるようになります。
IAPの設定を記述したJSONをgcloudコマンドに読み込ませることで可能です。
{
"access_settings": {
"allowed_domains_settings": {
"enable": true,
"domains": [
"example.com",
"*.example.com"
]
}
}
}
gcloud iap settings set setting.json --project=$PROJECT --resource-type=iap_web
ピリカサポーターズクラブのデプロイ処理では、Cloud Runのデプロイ後にこのコマンドが毎回実行されるようにしてあります。
ローカルでの動作
クラウド上に展開されている仕組みをローカルでも同様に動作するようにdocker-composeを使用しました。 クラウド上で動作しているCloud RunもDockerfileから構築して起動されていますので、ローカルとクラウドで動作が異なる部分に関しても環境変数を渡すことでほとんど同じ動作をさせることができます。
フロントエンドはViteで開発しているため、nodeイメージから直接起動し、npm run でViteを起動しています。
フロントエンドと同じホストにAPIをホストし、フロントエンドから/api/ 等の絶対パスでアクセスできるようにするため、vite.config.ts に proxy 設定を入れることで、Viteを経由してバックエンドにできるようにしています。
また、ログインセッションを管理するCookieを扱うため、HTTPSで動作する必要があるため、localhost の証明書を発行してマウントしておき、Viteがhttpsで起動するようにしています。
// vite.config.ts import { defineConfig } from "vite"; import react from "@vitejs/plugin-react"; import * as fs from "fs"; import svgr from "vite-plugin-svgr"; const dev_host = process.env.DEV_HOST ? process.env.DEV_HOST : "127.0.0.1"; const dev_backend = process.env.DEV_BACKEND ? process.env.DEV_BACKEND : "http://localhost:8201"; export default defineConfig({ plugins: [react(), svgr()], server: { host: dev_host, port: 8281, https: { key: fs.readFileSync("../../certs/key.pem"), cert: fs.readFileSync("../../certs/cert.pem"), }, proxy: { "/api": { target: dev_backend, changeOrigin: true, }, }, }, });
GCPサービスのローカルエミュレーター
GCP固有のサービスをローカルでテストするために、それぞれのサービスのエミュレータがあるとローカルでも同様に動作させることができ便利です。 ピリカサポーターズクラブの開発では、以下のコンテナ設定使ってGCPサービスのローカルエミュレーターを実現しています。
Cloud Storage
fsouza/fake-gcs-server を使用しています。
storage-emulator: image: fsouza/fake-gcs-server command: -scheme http -port 4443 -external-url http://storage-emulator:4443 -public-host storage-emulator:4443 volumes: - storage:/storage
注意点としては、バケットにあたるディレクトリをVolumesの中にあらかじめ作っておく必要があることです。開発環境の初回起動時に以下のコマンドを使ってバケットのディレクトリを作成します。
# public という名前のバケットを作成する $ docker-compose exec storage-emulator mkdir -p /storage/public
環境変数STORAGE_EMULATOR_HOSTに、切り替え先のエミュレータのURL(今回ですとhttp://storage-emulator:4443)を指定しておくと、Cloud Storageクライアントライブラリの標準動作でアクセス先のホストが切り替わります。
Cloud Tasks
aertje/cloud-tasks-emulator を使用しています。
複数のキューが必要であれば、-queueオプションを複数指定すれば問題ありません。
tasks-emulator: image: ghcr.io/aertje/cloud-tasks-emulator:latest command: -host 0.0.0.0 -port 9000 -queue "projects/<<PROJECT_NAME>>/locations/asia-northeast1/queues/<<QUEUE_NAME>>" ports: - "9000:9000"
環境変数にtasks-emulator:9000を渡しておき、以下のようなコードでクラウド動作とローカルエミュレータ動作を切り替えています。
def get_tasks_client(credentials: Credentials, emulator: str | None) -> CloudTasksClient: """Cloud Tasksのクライアントを取得する :param credentials: 認証 :param emulator: エミュレーターURL :return: """ if emulator: channel = grpc.insecure_channel(emulator) transport = CloudTasksGrpcTransport(channel=channel) return CloudTasksClient(transport=transport) else: return CloudTasksClient(credentials=credentials)
その他のエミュレーター
Cloud Pub/Subにもエミュレーターが存在します。
今回は使用しませんでしたが、SNSピリカの開発では使用しています。
SNSピリカにどのように展開していくか
ピリカサポーターズクラブを開発するにあたって構築したインフラを中心とした仕組みをここまでご紹介してきました。 1記事の長さとしてはかなり長くなってしまいましたが、GCPを使用した開発をお考えの方の参考になれば幸いです。
実際、開発チームは年始よりこの基盤を使った開発をしてきましたが、SNSピリカの開発で困っていたことの多くを解消することができています。 今回開発した技術をSNSピリカにも反映すればより効率的に開発を進められそうな手応えがあり、SNSピリカの基盤にも少しずつ取り入れていきます。
*1:例示用に構成はいじってあるのでこのまま動作はしません