こんにちは、ピリカ開発チームの九鬼です。
AppSheetを使うと、スプレッドシートをデータベース代わりにしたアプリをノーコードで作成できます。AppSheetでは画像を表示することもできるのですが、設定すればGoogle Cloud Storage(GCS)上にある画像も参照することができます。
そこで、スプレッドシート+GCSに毎日データを追加し、AppSheetアプリでデータを見られる仕組みを構築してみました。
背景
タカノメにおいて、1日あたり数万を超える地点の撮影データが蓄積されています。データの閲覧用ページはあるものの、統計的な結果を見るためにカスタマイズしていました。その関係で、
- 各画像が正しく撮影されているか
- ごみが多い地点がどんな画像か
を地点ごとにチェックするには適していませんでした。その仕組みをつくるには数週間を要するため、すぐに対応するのは難しい状況でした。
対策を探していたところ、AppSheetで要件を満たせそうなことがわかりました。AppSheetであればUIをすぐに変更することができ、かつデータをリスト・マップ・画像付きで柔軟に確認することができるためです。そこで、AppSheetで撮影データをチェックするためのアプリを作ってみました。
以下、作成したアプリのイメージです。

システムイメージ
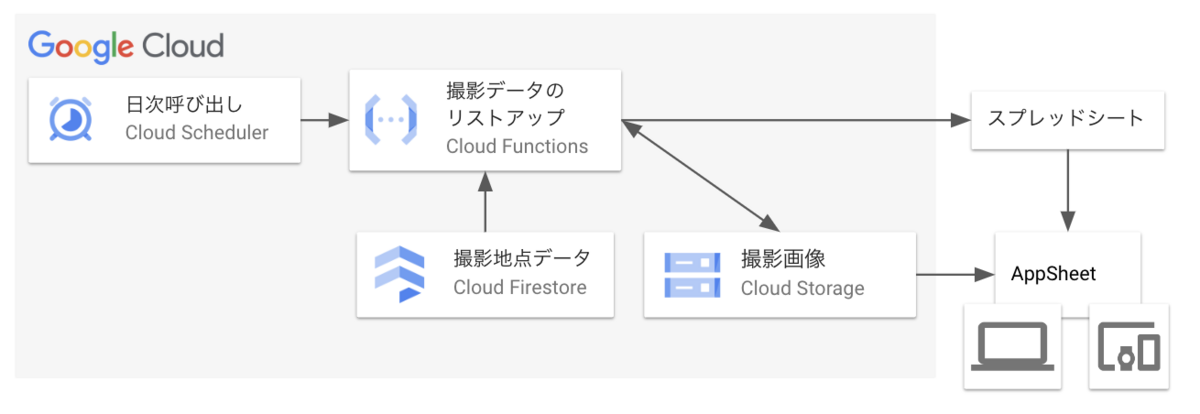
Cloud Functionsにて、撮影地点一覧の取得・保存を定期的に行っています。その結果をスプレッドシートないしはStorageの特定バケットに保存し、AppSheetで参照しています。
システム構築にあたって判明した点
GCS上にある画像を参照するにあたって、下記2点がネックとなっていました。特に1番目は公式ドキュメントがなかったため、AppSheetの挙動を見て実装しました。
GCSの保存場所は固定
バケット名は自由に設定可能ですが、オブジェクトの先頭は/DocId_xxx(xxxはスプレッドシートのファイルID)/にから始まる必要があります。これ以外の接頭詞はAppSheetから認識されず、画像を参照しようとしても404になります。また、ファイルIDにあるハイフンはすべてアンダースコアに置き換える必要があります。


なお、スプレッドシート上でGCSの画像パスを記載する場合、/DocId_xxx/以降のパスをセルに記載すればOKです。例えば、画像が/DocId_xxx/hoge/fuga.jpgで保存されている場合、hoge/fuga.jpgという文字列をセルに保存しておけばアクセスできます。
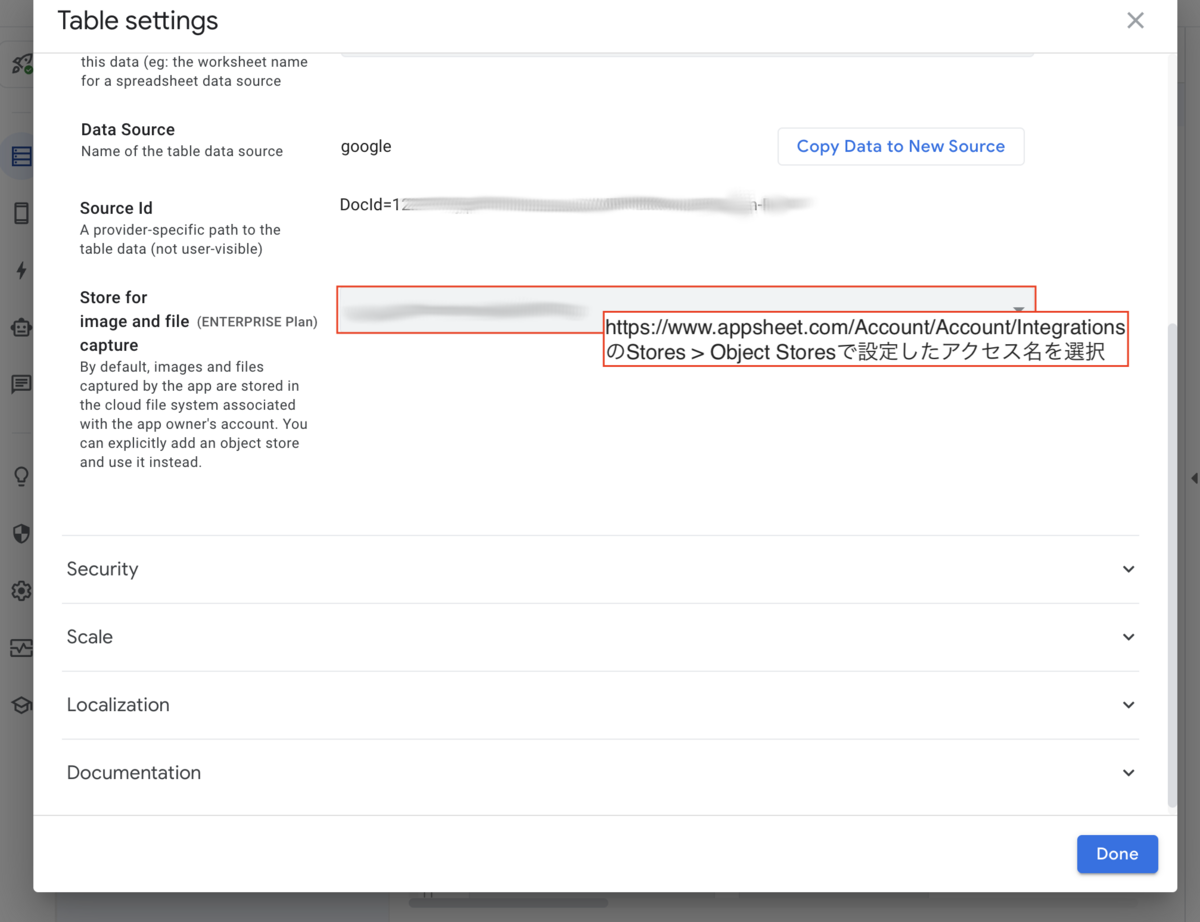
AppSheet上では、Dataの設定でTypeをImageとし、Table settings > Store for image and file captureでGCSへのアクセス設定を指定すれば画像が読み込み可能になります。
画像をアプリ外でアクセスできないようにする
デフォルトでは、署名付きURLで画像が配信されます。これにより、署名がない状態での画像アクセスは制限されます。ただし、画像の実態はCDNから配信されているため、デベロッパツール等でCDN上のURLを参照すれば誰でもアクセス可能です。
もし画像をよりセキュアにした場合、Security > Options > Secure Image access を入れることができます。ONにした後、最大で1日以内に反映されます。

以上になります。皆様良いお年を!